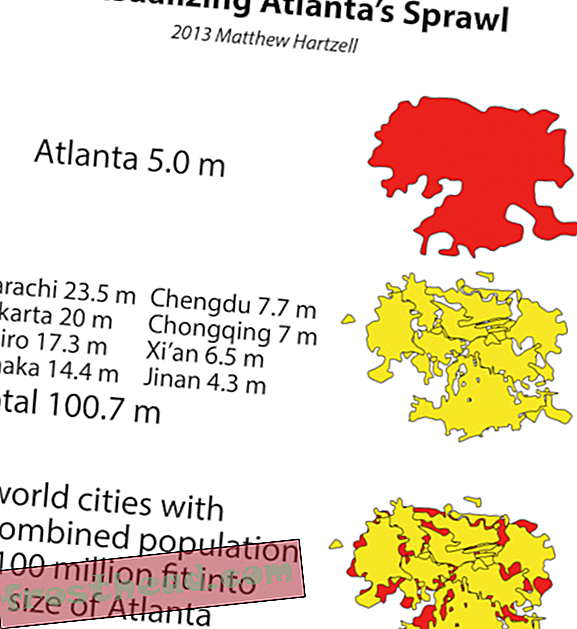
Me kaikki tiedämme, että maailmoissamme on paljon enemmän tietoa kuin ennen. Mitä enemmän, hyvin, suurin osa meistä on melko avuttomia.
Asiaan liittyvä sisältö
- Infographics kautta aikojen korosta tieteen visuaalinen kauneus
- Miksi Google-influenssatrendit eivät pysty seuraamaan fluntaa (vielä)
Tässä on korvaamaton nugget kaikesta kyseisestä tiedosta, IBM: n supertietokonekehityksestä vastaavan kaverin Dave Turekin kiitokset: Vuodesta 2003 ja työskennellessään taaksepäin ihmiskunnan historiaan, IBM: n laskelmien mukaan tuotimme viisi eksabyyttiä - se on viisi miljardia gigatavua tietoa. Viime vuonna vuorottelimme niin paljon tietoa kahden päivän välein. Ensi vuoteen mennessä, ennustaa Turek, teemme sen 10 minuutin välein.
Mutta miten tämä on mahdollista? Kuinka tiedosta tuli tällainen digitaalinen kudzu? Yksinkertaisesti sanottuna, joka kerta, kun matkapuhelimesi lähettää GPS-sijaintinsa, joka kerta kun ostat jotain verkosta, joka kerta kun napsautat Facebookissa Tykkää-painiketta, lisäät uuden digitaalisen viestin pulloon. Ja nyt valtameret ovat melko hyvin peitetty niiden kanssa.
Ja se on vain osa tarinaa. Tekstiviestit, asiakasrekisterit, pankkiautomaatit, turvakamerakuvat ... luettelo jatkuu ja jatkuu. Buzzword tämän kuvaamiseksi on ”Big Data”, tosin tuskin se antaa oikeutta luomamme hirviön mittasuhteelle.
Se on viimeisin esimerkki tekniikasta, joka osoittaa kykymme käyttää sitä. Tässä tapauksessa emme ole vielä alkaneet kiinni kyvystämme kaapata tietoja, minkä vuoksi nykypäivän suosituin johtoryhmä on se, että tulevaisuus kuuluu yrityksille ja hallituksille, jotka voivat ymmärtää kaiken heidän tietonsa kerätä, mieluiten reaaliajassa.
Yrityksillä, jotka osaavat tulkita jokaista asiakkaidensa taakse jättämää digitaalista leipärataa, on etulyöntiasema, ajattelu menee - ei vain kuka osti mitä missä viimeisen tunnin aikana, vaan myös siitä, ovatko he tweettinneet siitä tai lähettäneet kuvan jonnekin sosiaalisten verkostojen pyörteeseen. Sama pätee kaupunkeihin, jotka voivat kerätä tietoja tuhansilta sensoreilta, jotka nyt pistettävät kaupunkimaisemaa ja muuttavat kaupunkielämän epämääräisyydet, kuten liikennevirrat, tiedeksi.
Ei ole yllättävää, että poliittiset kampanjat jo harjoittavat syöksyä, raivostuneesti kaivosta tietoja osana keskittymistään ”nanomääräämiseen” toimiviin äänestäjiin, jotta he tietävät tarkalleen, kuinka asettaa heille äänet ja raha. Johtopäätösten joukossa analyytikot ovat New York Timesin kolumnisti Thomas Edsallin mukaan päättäneet, että republikaanit pitävät mieluummin ”The Office ”- ja Cracker Barrel -ravintolaa, kun taas demokraatit katsovat todennäköisemmin” Late Night With David Letterman ”ja syövät Chuck E: ssä. Juusto.
Tämä kiire digitaalisen flotsamin tulkinnasta selittää sen, miksi Google ilmoitti viime viikolla aloittavansa BigQuery-nimisen tuotteen, joka voi skannata teratavuja tietoja sekunneissa, kutsun BigQuery-ohjelmaan. Ja miksi Splunk-nimisen startupin, jolla on tekniikka, joka pystyy analysoimaan valtavia määriä asiakas- ja transaktiotietoja, näki sen osakkeiden arvo nousevan lähes 90 prosenttia päivästä, jolloin se julkistettiin viime kuussa. Tämä yritykselle, joka menetti viime vuonna 11 miljoonaa dollaria.
Tietojen tutkijan nousu
Mutta edes pääsy parhaisiin tiedon salauksen purkutyökaluihin ei takaa suurta viisautta. Hyvin harvoissa yrityksissä on henkilöstöä, joka on koulutettu paitsi arvioimaan tietovuoria - mukaan lukien kuormia rakenteettomia pieniä osia miljoonista Facebook-sivuista ja älypuhelimista - vaan myös tekemään jotain sen kanssa.
McKinsey Global Insitute julkaisi viime vuonna raportin, jossa kuvataan ”Big Data” ”seuraavana innovaatiorajana”, mutta ennustettiin myös, että vuoteen 2018 mennessä Yhdysvaltojen yrityksillä on vakava kyky puutetta tarvittavien analyyttisten taitojen suhteen - niin monta 190 000 ihmistä. Ja se väittää, että vielä 1, 5 miljoonaa johtajaa on koulutettava tekemään strategisia päätöksiä, kun tiedot tulevat uuteen suuntaan.
Kaikki eivät kuitenkaan usko Big Data -taiteen taikaan. Penn's Wharton School of Business -yrityksen markkinointiprofessori Peter Fader ei ole vakuuttunut siitä, että enemmän tietoa on parempi. Ei sitä, että hänen mielestään yrityksen ei pitäisi yrittää oppia niin paljon kuin pystyy asiakkaistaan. Se on vain, että nyt keskitytään niin paljon tietoihin, että hänen mielestään volyymi arvostetaan todelliseen analyysiin verrattuna.
Tässä on Faderin otto äskettäisestä MIT: n Technology Review -haastattelusta : “Edes loputtomalla tiedolla aiemmasta käytöksestä, meillä ei usein ole tarpeeksi tietoa tulevaisuuden merkityksellisten ennusteiden tekemiseksi. Itse asiassa mitä enemmän tietoja meillä on, sitä enemmän väärää luottamusta meillä on. Tärkeää on ymmärtää, mitkä ovat rajamme, ja käyttää parasta mahdollista tiedettä aukkojen täyttämiseen. Kaikki maailman tiedot eivät koskaan saavuta tätä tavoitetta meille. ”
Kuka on tietosi?
Tässä on esimerkki siitä, kuinka Big Data -sovellusta käytetään suurten ongelmien ratkaisemiseen:
- He tietävät, milloin he ovat olleet huonoja tai hyviä: Vaikka suurin osa yrityksistä keskittyy analysoimaan asiakkaitaan, Amazon pisteyttää pisteitä käyttämällä Big Data -sovellusta heidän auttamiseen.
- Nastatutkimus: Haluatko tietää, mitkä sonnit kutevat tuottavimpia lypsylehmiä? Meijeriteollisuus on suunnitellut tavan purkaa numeroita.
- Tietoihin perustuva diagnoosi: SUNY Buffalon tutkijat analysoivat suuria tietosarjoja pyrkiessään selvittämään, onko multippeliskleroosin ja ympäristötekijöiden välillä yhteys, kuten esimerkiksi se, ettei altistuminen riittävälle auringonvalolle.
- Etsitään vaikeuksia: Recorded Future -niminen yritys louhii sosiaalisista verkostoista, hallituksista ja rahoitussivustoista saatuja tietoja ennustaakseen, kuinka väestönkasvu, vesipula ja äärimmäiset sääolosuhteet voivat johtaa tuleviin poliittisiin levottomuuksiin ja terrorismiin.
Videobonus: Tietojen kaappaaminen on yksi asia. Sen tekeminen houkuttelevaksi ja ymmärrettäväksi on aivan toinen haaste. David McCandless voittaa "tietokarttoja" tässä TED-puheessa.